Data Analysis
Analysis
allows you to solve problems by examining the geographic patterns in your data
and observing relationships between features. The methodology you use to solve
problems can be very simple—sometimes just by making a map you're doing analysis—or
more complex, involving models that mimic the real world by combining several
data layers and processes.
Because the ArcGIS® geoprocessing framework
includes ModelBuilder™, it's easy to execute even the
most complex analyses. Model criteria and methodology can be quickly adjusted,
and you can run your model as many times as necessary to test alternative solutions.
![]()
You can use geoprocessing tools for analyzing your data.
Modeling your workflow
So far in
this course, you've combined individual geoprocessing
tools in meaningful sequences to create new data. However, the more complex
your geoprocessing workflow becomes, the more
difficult it is to keep track of the various datasets, processing procedures,
parameters, and assumptions that you have used. One of the easiest ways to
overcome this difficulty is to create a spatial model in ModelBuilder.
Many types of models are used in
More about spatial models
Roughly
speaking, spatial models are
In this
course, the type of model you'll work with is a suitability model. A
suitability model in
Suitability
models are not mathematically predictive. They do not estimate the value of a
geographic phenomenon at a given point in space and time, such as the amount of
rainfall that
A model can
be rigorous without being statistical. For example, suitability models often
involve reaching a balance of opinion among interested parties as to what
factors define suitability. There are formal systems, such as the
Spatial
models are often not purely one thing or another. Suppose you want to find the
best available land in central
Another
quality of spatial models is complexity and interrelationship of parts. Suppose
you are looking for a site on which to build a house and you decide that all
that matters is that you build on vacant land. Any
You have
introduced a certain degree of complexity. You have multiple criteria to
satisfy and most of these criteria lie on a scale of satisfaction. (How expensive is too expensive? How high up a hill? How
close is close to a golf course? How low is low-crime?)
You also
have interrelationship of parts, since these criteria have different amounts of
relative importance. For example, what if there are no low-crime neighborhoods
in your desired price range? What if there are no high schools near hills?
Which conditions play a larger part in your final decision?
Why build models?
Building
models has several advantages, the most important of which are described below.
Automate the geoprocessing workflow
Models help you manage the complex combination of assumptions, tools, datasets,
and other factors associated with your analysis. Models can be easily modified
so that you can explore alternative outcomes or accommodate new information.
The model updates dynamically. Changes to one part of the model are
automatically carried through to the rest of the model.
Share geoprocessing knowledge
Models easily communicate what is being done. Models are represented as flow
charts with distinct symbols for input data, spatial operations, and output
data. The structure of the model and flow of data processing are apparent. This
makes it easy for you and others to see the model's scope and understand how it
works.
Record and document methodology
Models allow for simple or sophisticated geoprocessing
workflows to be captured and documented. You can document the sources of input
data and assumptions you made in the model for future use or to share your work
with others. You'll learn more about documentation in Module 5 of this course.
Add complexity as needed
Models allow you to assemble simple and complex processes into one tool. For
complex processes, you can create a separate model. These "submodels" can be added to primary models, allowing
you to easily incorporate components developed by experts in various
disciplines.
The anatomy of a model
A model in ArcGIS is a tool that defines a set of rules and procedures
for representing a phenomenon or predicting an outcome. Models consist of one
or more processes. (Remember, a process is simply a tool and its parameter
values.) In its simplest form, a model may consist of a single process.
Typically, a model is built using several connected processes so that the
output of one process becomes the input to another process.
In ModelBuilder, models are represented as flow charts with
distinct symbols for each type of component. Model components are referred to
as elements. Elements are connected together via connector lines that
serve to create processes as well as show processing flow.
Below is a
list of the elements in ModelBuilder:
· Tools—the same tools that are in ArcToolbox™ are available for use in models. Tool elements
are represented by gold rectangles in ModelBuilder.
· Project data—any data that exists
before a tool executes. Project data will typically be used as the input to a
tool in a model. Project data elements are represented by blue ovals.
· Derived data—data created by
running a geoprocessing operation on existing project
data. Derived data from one process can serve as input data for another
process. Derived data elements are represented by green ovals.
· Values—reference tool parameters
other than datasets; for example, the buffer distance for the Buffer tool.
Value elements are represented by light blue ovals.
· Derived values—reference values
that are created by running a tool, such as the output value from the Calculate
Default Cluster Tolerance tool. You'll work with derived value elements in
Module 4 of this course. Derived value elements are represented by light green
ovals.
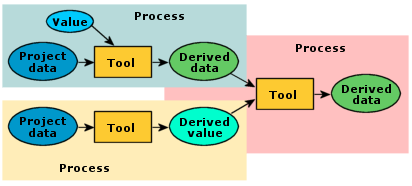
Models
typically contain several processes, and they can be chained together so that
the derived output from one process becomes the input for another process. The
conceptual model shown here contains three processes.
Any element in a model that isn't a tool is a variable.
Variables can be thought of as placeholders for datasets or other tool
parameters. Variable values can be easily changed, and they can be shared
between processes in a model.
![]() Ingredients of
a good model
Ingredients of
a good model
This course
is about how to use the ArcGIS geoprocessing
framework; it is not about modeling methodology. Still, it won’t hurt to
mention a few points to keep in mind when you start building your own models.
Choose your input factors carefully
This may seem obvious, but it means making difficult
decisions in practice. A model is necessarily a simplification of reality. If
you try to include every factor that has a possible bearing on the result, your
model will never be done. (Perhaps a good model never is quite done.) At the
same time, you don’t want to omit crucial factors, the absence of which would
undermine your conclusions.
Consult experts if you're not one
In practice, there are constraints on the factors you
choose to include. One of the principal constraints is often the limits of your
own knowledge. Suppose you are building a model to identify streams that are
good salmon habitat. Good habitat includes woody debris, which shields the
water from direct sunlight, thus lowering its temperature. If you don’t know
that this matters to the fish, you will probably not build a satisfactory
model. Talking to experts and reading papers can help acquaint you with the
most important issues.
Be alert to the interplay of factors
In choosing a location for a ski resort, you prefer
higher elevations that get more snow. You also want proximity to existing roads
so that development costs are lower. But these two factors may be in conflict:
the higher you go, the farther you get from existing roads. You have thus built
into your model conditions that possibly cannot be simultaneously satisfied. If
you don’t realize this, you won’t know why your model fails to find any highly
suitable sites. Once you understand the problem, you can devise a solution. For
example, if you decide that elevation is the more important factor, you might
set a threshold value for distance to roads (such as that the chosen site must
be within five miles of a road) and not use proximity to roads to further
evaluate suitability.
Know your data
One of the constant temptations of
Another
danger lies in combining data layers that have different scales of accuracy. If
you overlay a dataset of roads that is accurate at the scale of 1:24,000 with a
dataset of streams that is accurate at the scale of 1:100,000, the locations of
streams with respect to roads will be incorrect. Neither your
Use proxies with caution
A typical modeling problem is not having exactly the
data that you need. A typical solution is to use proxies. A proxy (also called
a surrogate) is a dataset that is used as a substitute for data you don’t have.
For your salmon habitat model, you may not have direct data on the amount of
woody debris in streams, and it may be impractical to acquire it. But you may
have a land cover layer that tells you which parts of your study area are
forested and which are not. By inferring that forested areas near streams
deposit woody debris, you can use land cover as a proxy measurement of debris.
There are
different kinds of proxies. Some are based on common-sense reasoning, as in the
example above. It is probably correct to infer the existence of woody debris
from the presence of trees. Other proxies are based on known associations. If
aphids are reliably found wherever there are roses, then roses may be used as a
proxy for aphids. Other proxies are based on a relation of component to whole.
In evaluating the difficulty of grading terrain, for example, you may decide to
use slope as a proxy. This has some validity, since steep land is harder to
grade than flat land, but there are other factors, such as geology, soil type,
and land cover, that influence grading difficulty as well.
If you use
slope as a proxy for grading difficulty (substituting a component for the
whole) and you then go on to use grading difficulty as a proxy for land
development cost (again substituting a component for the whole), this part of
your model may not be too reliable.
There is
nothing wrong with proxies as such—the danger lies in stretching them too far
or in counting on them too much.
Live and learn
Keep the above cautions in mind but don’t be afraid to
model. Models evolve. The most imperfect model is still a starting point and
has the value of introducing systematic rational analysis to the
decision-making process. Welcome criticism of your model. Remember, ModelBuilder makes it easy to add, remove, and modify model
processes as necessary.
Model element states
To run a
model is to run all of the processes that compose it. The readiness of a
process to run depends on the state of its elements.
A process
can be in one of three states: not ready to run, ready to run, or has been run.
If any element in a process is not ready to run, the process as a whole is not
ready to run. The elements of a process are usually in the same state.
Element states have unique symbology. An
element that is not ready to run is white. An element that is ready to run is
colored. An element that has been run adds a dropshadow
to its color.
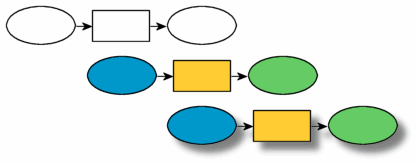
The three
states of a process shown from top to bottom are: not ready to run, ready to
run, and has been run. The state of a process depends on the state of its
elements.
An element's readiness to run can be affected by various
factors. One factor is connectivity. A tool that is not connected to an input
element will not be ready to run. (The converse is not true. A project data
element can be ready to run without being connected to a tool.)
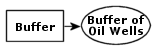
Tool
elements are automatically connected to output data elements, but not to input
data elements. In this example, there is no input to the Buffer tool;
therefore, it is not ready to run.
Another factor is specification. In the graphic below, the
three elements are connected, but the tool parameters have not been specified.
If an element's parameters are not fully specified, the element will not be
ready to run.

Although
the input data element is ready to run, the parameters of the Add Field tool
have not been defined; therefore, the process as a whole is not ready to run.
The third factor is data accessibility. A project data
element represents a spatial dataset. If this dataset is
inaccessible to ModelBuilder (for example, if the
relevant file has been deleted from its specified workspace), the project data
element will not be ready to run. If the project data element is not
ready to run, the tool and derived data elements connected to it cannot be
ready to run.

In this
example, the elements are connected and their parameters are fully specified.
The problem is that ModelBuilder cannot find the
input data it needs.