Geographic
data models
Two common
data models used to represent geographic data are the vector data model and the
raster data model.
Vector
data model
The vector
data model is based on the assumption that the earth's surface is composed of
discrete objects such as trees, rivers, lakes, etc. Objects are represented as
point, line, and polygon features with well-defined boundaries. Feature
boundaries are defined by x,y
coordinate pairs, which reference a location in the real world.
· Points are defined by a single x,y coordinate pair
· Lines are defined by two or more x,y coordinate pairs
· Polygons are defined by lines that
close to form the polygon boundaries
In the
vector data model, every feature is assigned a unique numerical identifier,
which is stored with the feature record in an attribute table.
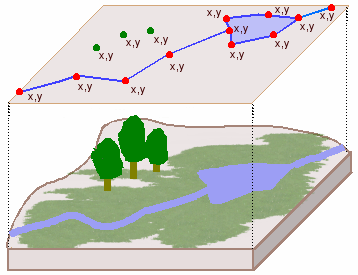
The vector data model represents
real-world features as points, lines, and polygons whose boundaries are defined
by x,y coordinate pairs.
Raster
data model
In the
raster data model, the earth is represented as a grid of equally sized cells.
An individual cell represents a portion of the earth such as a square meter or
a square mile.
Unlike the
vector data model, where x,y coordinates are used to
define feature shapes and locations, in the raster data model, only one x,y coordinate pair is normally present. This x,y coordinate pair (called the
origin) is used to define the location of every cell. That is, each cell's
location is defined in relation to the origin.
Each
raster cell is assigned a numeric value, which can represent any kind of
information about that geographic location—an elevation measurement in meters,
for example, or a code number that specifies a type of vegetation.
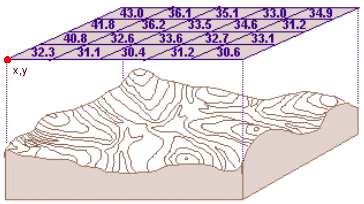
The raster data model represents
geographic data, here elevation, as rows and columns of equally sized cells.
One corner of the raster must be defined by an x,y coordinate pair.
Which
data model should you use?
Both the
vector and raster data models are useful for representing geographic data, but
one may be more appropriate than the other when it comes to representing a
particular type of geographic data or answering different kinds of questions.
In general, use the vector data model when you want to represent features that
have discrete boundaries. For example, a building is well represented as a
polygon feature with x,y
coordinates recorded for its corners.
The raster
data model can be used to represent discrete features as well. A building in
the raster data model, for example, would be represented as a group of
connected cells with the same value, the code value for building. Representing
discrete features in the raster data model requires less storage space than
storing them in the vector data model, but is less accurate.
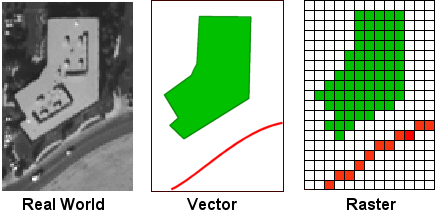
The vector data model represents
geographic features with exactly defined boundaries, while the raster data
model represents them as cells of the same value. Notice that the shapes of the
raster building and road don't seem as similar to the real-world shapes as the
vector shapes.
The raster
data model is very useful for representing continuous geographic data; that is,
phenomena such as elevation, precipitation, and temperature, which don't have
well-defined boundaries and which usually change gradually across a given area.
When used
to represent continuous data, each raster cell value is a measure of the
phenomenon being modeled. For example, in an elevation raster, each cell value
represents the elevation of a particular area. The raster data model is
commonly used for spatial analysis and modeling.